No products in the cart.
Course Introduction:
What you’ll learn
- Process Bigdata using Hadoop tools
- How to install Hadoop on Linux
- Use HDFS and MapReduce for storing and analyzing data at scale.
- Use Pig and Hive to create scripts to process data on a Hadoop cluster in more complex ways.
- Analyze relational data using Hive and MySQL
- Analyze non-relational data using HBase, and MongoDB
- Fetching data through Twitter by using Apache Flume
- Understand how Hadoop jobs work in the background
- Publish data to your Hadoop cluster using Sqoop, and Flume
- Hands ‘on More than 13 real-time Hadoop projects
Requirements: –
- You will need to have a background in IT. The course is aimed at Software Engineers, System Administrators, DBAs who want to learn about Big Data
- Knowing any programming language will enhance your course experience
- The course contains demos you can try out on your own machine.
- A basic familiarity with the Linux command line will be very helpful.
Description: –
In this course, you will learn Big Data using the Hadoop Ecosystem. Why Hadoop? It is one of the most sought after skills in the IT industry. The average salary in the US is $112,000 per year, up to an average of $160,000 in San Fransisco (source: Indeed).
The course is aimed at Software Engineers, Database Administrators, and System Administrators that want to learn about Big Data. Other IT professionals can also take this course but might have to do some extra research to understand some of the concepts.
You will learn how to use the most popular software in the Big Data industry at the moment, using batch processing as well as real-time processing. This course will give you enough background to be able to talk about real problems and solutions with experts in the industry. Updating your LinkedIn profile with these technologies will make recruiters want you to get interviews at the most prestigious companies in the world.
Introduction: –
- Bigdata:- Big data is a term that describes the large volume of data – both structured, semi-structured and unstructured – that cannot be stored and processed using conventional technologies like databases.
- Hadoop:– Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware.
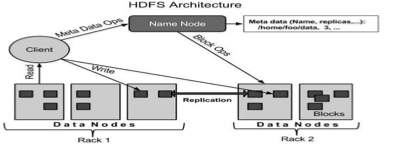
- Hdfs (Hadoop distributed file system):–
- The Hadoop Distributed File System (HDFS) is the underlying file system of a Hadoop cluster. It provides scalable, fault-tolerant, rack-aware data storage designed to be deployed on commodity hardware. Several attributes set HDFS apart from other distributed file systems. Among them, some of the key differentiators are that HDFS is:
- Designed with hardware failure in mind
- Built for large datasets, with a default block size of 128 MB
- Optimized for sequential operations
- Rack-aware
- cross-platform and supports heterogeneous clusters
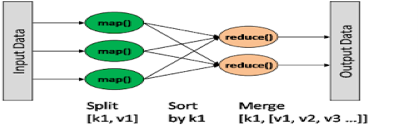
- MapReduce:-
- MapReduce is a framework for processing highly distributable problems across huge datasets using a large number of computers (nodes), collectively referred to as a cluster. The framework is inspired by the map and reduce functions commonly used in functional programming.
- In the “Map” step, the master node takes the input, partitions it up into smaller sub-problems, and distributes them to worker nodes. The worker node processes the smaller problem and passes the answer back to its master node. In the “Reduce” step, the master node then collects the answers to all the sub-problems and combines them in some way to form the output – the answer to the problem it was originally trying to solve.
- Eco-system:-
-
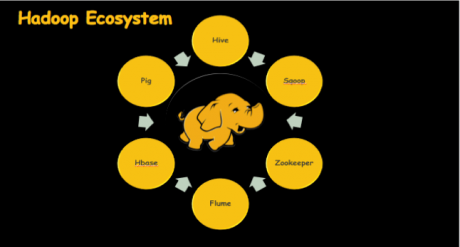
- Hive:- Hive is a data warehouse infrastructure tool to process structured data in Hadoop. It resides on top of Hadoop to summarize Big Data and makes querying and analyzing easy.
- Pig:- Apache Pig is a high-level platform for creating programs that run on Apache Hadoop. The language for this platform is called Pig Latin. Pig can execute its Hadoop jobs in MapReduce, Apache Tez, or Apache Spark. Pig Latin abstracts the programming from the Java MapReduce idiom into a notation which makes MapReduce programming high level, similar to that of SQL for RDBMSs. Pig Latin can be extended using User Defined Functions (UDFs) which the user can write in Java, Python, JavaScript, Ruby or Groovy and then call directly from the language.
- HBase:- HBase is a distributed column-oriented database built on top of the Hadoop file system. It is an open-source project and is horizontally scalable.
- Zookeeper:- ZooKeeper is a distributed coordination service to manage a large set of hosts. Co-ordinating and managing a service in a distributed environment is a complicated process. ZooKeeper solves this issue with its simple architecture and API. ZooKeeper allows developers to focus on core application logic without worrying about the distributed nature of the application.
- Sqoop:- Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and external datastores such as relational databases, enterprise data warehouses.
- Flume:- Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming data into the Hadoop Distributed File System (HDFS). It has a simple and flexible architecture based on streaming data flows, and is robust and fault tolerant with tunable reliability mechanisms for failover and recovery.
-

Add a note